Automatic transliteration with LSTM
By Tigran Galstyan, Hrayr Harutyunyan and Hrant Khachatrian.
Many languages have their own non-Latin alphabets but the web is full of content in those languages written in Latin letters, which makes it inaccessible to various NLP tools (e.g. automatic translation). Transliteration is the process of converting the romanized text back to the original writing system. In theory every language has a strict set of romanization rules, but in practice people do not follow the rules and most of the romanized content is hard to transliterate using rule based algorithms. We believe this problem is solvable using the state of the art NLP tools, and we demonstrate a high quality solution for Armenian based on recurrent neural networks. We invite everyone to adapt our system for more languages.
Contents
Problem description
Since early 1990s computers became widespread in many countries, but the operating systems did not fully support different alphabets out of the box. Most keyboards had only latin letters printed on them, and people started to invent romanization rules for their languages. Every language has its own story, and these stories are usually not known outside their own communities. In case of Armenian, some solutions have been developed, but even those who knew how to write in Armenian characters, were not sure that the readers (r.g. the recipient of the email) would be able to read that.
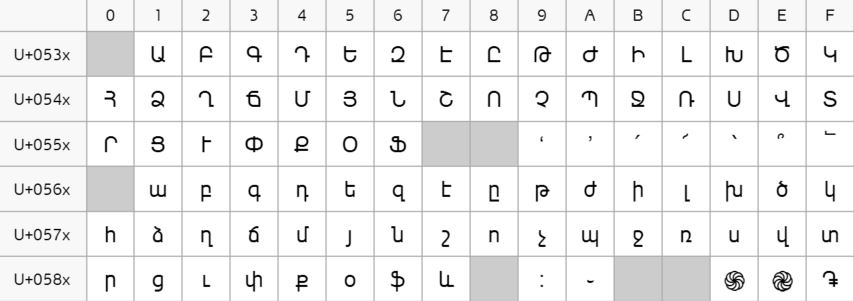 |
|---|
| Armenian alphabet in the Unicode space. Source: Wikipedia |
In the Unicode era all major OSes started to support displaying Armenian characters. But the lack of keyboard layouts was still a problem. In late 2000s mobile internet penetration exploded in Armenia, and most of the early mobile phones did not support writing in Armenian. For example, iOS doesn’t include Armenian keyboard and started to officially support custom keyboards only in 2014! The result was that lots of people entered the web (mostly through social networks) without having access to Armenian letters. So everyone started to use some sort of romanization (obviously no one was aware that there are fixed standards for the romanization of Armenian).
Currently there are many attempts to fight romanized Armenian on forums and social networks. Armenian keyboard layouts are developed for every popular platform. But still lots of content is produced in non-Armenian letters (maybe only Facebook knows the exact scale of the problem), and such content remains inaccessible for search indexing, automated translation, text-to-speech, etc. Recently the problem started to flow outside the web, people use romanized Armenian on the streets.
 |
|---|
| Romanized Armenian on the street. Source: VKontakte social network |
There are some online tools that correctly transliterate romanized Armenian if its written using strict rules. Hayeren.am is the most famous example. Facebook’s search box also recognizes some romanizations (but not all). But for many practical cases these tools do not give a reasonable output. The algorithm must be able to use the context to correctly predict the Armenian character.
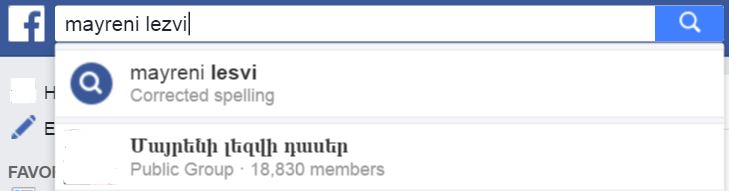 |
|---|
| Facebook’s search box recognizes some romanized Armenian. Note that the spelling suggestion is not for Armenian. |
Finally, there are debates whether these tools actually help fighting the “translit” problem. Some argue that people will not be forced to use Armenian keyboard if there are very good tools to transliterate. We believe that the goal of making this content available for the NLP tools is extremely important, as no one will (and should) develop, say, language translation tools for romanized alphabets.
Wikipedia has similar stories for Greek, Persian and Cyrillic alphabets. The problem exists for many writing systems and is mostly overlooked by the NLP community, although it’s definitely not the hardest problem in NLP. We hope that the solution we develop for Armenian might become helpful for other languages as well.
Data processing
We are using a recurrent neural network that takes a sequence of characters (romanized Armenian) at its input and outputs a sequence of Armenian characters. In order to train such a system we take a lot of text in Armenian, romanize it using probabilistic rules and give them to the network.
Source of the data
We chose Armenian Wikipedia as the easiest available large corpus of Armenian text. The dumps are available here. These dumps are in a very complicated XML format, but they can be parsed by the WikiExtractor tool. The details are in the Readme file of the repository we released today.
The disadvantage of Wiki is that it doesn’t contain very diverse texts. For example, it doesn’t contain any dialogs or non formal speech (while social networks are full of them). On the other hand it’s very easy to parse and it’s quite large (356MB). We splitted this into training (284MB), validation (36MB) and test (36MB) sets, but then we understood that the overlap between training and validation sets can be very high. Finally we decided to use some fiction text with lots of dialogs as a validation set.
Romanization rules
To generate the input sequences for the network we need to romanize the texts. We use probabilistic rules, as different people prefer different romanizations. Armenian alphabet has 39 characters, while Latin has only 26. Some of the Armenian letters are romanized in a unique way, like ա-a, բ-b, դ-d, ի-i, մ-m, ն-n. Some letters require a combination of two Latin letters: շ-sh, ժ-zh, խ-kh. The latter is also romanized to gh or even x (because this one looks like Russian х which is pronounced the same way as Armenian խ).
But the main obstacle is that the same Latin character can correspond to different Armenian letters. For example c can come from both ց and ծ, t can come from both տ and թ, and so on. This is what the network has to learn to infer from the context.
We have created a probabilistic mapping, so that each Armenian letter is romanized according to the given probabilities. For example, ծ is replaced by ts in 60% of cases, c in 30% of cases, and & in 10% of cases. The full set of rules are here and can be browsed here.
 |
|---|
| Some of the romanization rules for Armenian |
Geographic dependency
The romanization rules vary a lot in different countries. For example, Armenian letter շ is mostly romanized as sh, but Armenians in Germany prefer sch, Armenians in France sometimes use ch, and Armenians in Russia use w (because w is visually similar to Russian ш which sounds like sh). There are many other similar differences that might require separate analysis.
Finally, Armenian language has two branches: Eastern and Western Armenian. These branches have crucial differences in romanization rules. Here we focus only on the rules for Eastern Armenian and those that are commonly used in Armenia.
Filtering out large non-Armenian chunks
Wikidumps contain some large regions where there are no Armenian characters. We noticed that these regions were confusing the network. So now when generating a chunk to give to the system we drop the ones that do not contain at least 33% Armenian characters.
This is a difficult decision, as one might want the system to recognize English words in the text and leave them without transliteration. For example, the word You Tube should not be transliterated to Armenian. We hope that such small cases of English words/names will remain in the training set.
Network architecture
Our search for a good network architecture started from Lasagne implementation of Karpathy’s popular char-rnn network. Char-rnn is a language model, it predicts the next character given the previous ones and is based on 2 layers of LSTMs going from left to right. The context from the right is also important in our case, so we replaced simple LSTMs with bidirectional LSTMs (introduced here back in 1995).
We have also added a shortcut connection from the input to the output of the 2nd biLSTM layer. This should help to learn the “easy” transliteration rules on this short way and leave LSTMs for the complex stuff.
Just like char-rnn, our network works on character level data and has no access to dictionaries.
Encoding the characters
First we define the set of possible characters (“vocabularies”) for the input and the output. The input “vocabulary” contains all the characters that appear in the right hand sides of the romanization rules, the digits and some punctuation (that can provide useful context). Then a special program runs over the entire corpus, generates the romanized version, and every symbol outside the input vocabulary is replaced by some placeholder symbol (#) in both original and romanized versions. The symbols that are left in the original version form the “output vocabulary”.
All symbols are encoded as one-hot vectors and are passed to the network. In our case the input vectors are 72 dimensional and the output vectors are 152 dimensional.
Aligning
After some experiments we noticed that LSTMs are really struggling when the characters are not aligned in inputs and outputs. As one Armenian character can be replaced by 2 or 3 Latin characters, the input and output sequences usually have different lengths, and the network has to “remember” by how many characters the romanized sequence is ahead of the Armenian sequence in order to print the next character in the correct place. This turned to be extremely difficult, and we decided to explicitly align the Armenian sequence by adding some placeholder symbols after those characters that are romanized to multi-character Latin.
 |
|---|
| Character level alignment of Armenian text with the romanization |
Also there is one exceptional case in Armenian: the Latin letter ‘u’ should be transliterated to 2 Armenian symbols: ու. This is another source of misalignment. We explicitly replace all ու pairs with some placeholder symbol to avoid the problem.
Bidirectional LSTM with residual-like connections
LSTM network expects a sequence of vectors at its input. In our case it is a sequence of one-hot vectors, and the sequence length is a hyperparameter. We used --seq_len 30 for the final model. This means that the network reads 30 characters in Armenian, transforms to Latin characters (it usually becomes a bit longer than 30), then crops up to the latest whitespace before the 30th symbol. The remaining cells are filled with another placeholder symbol. This ensures that the words are not split in the middle.
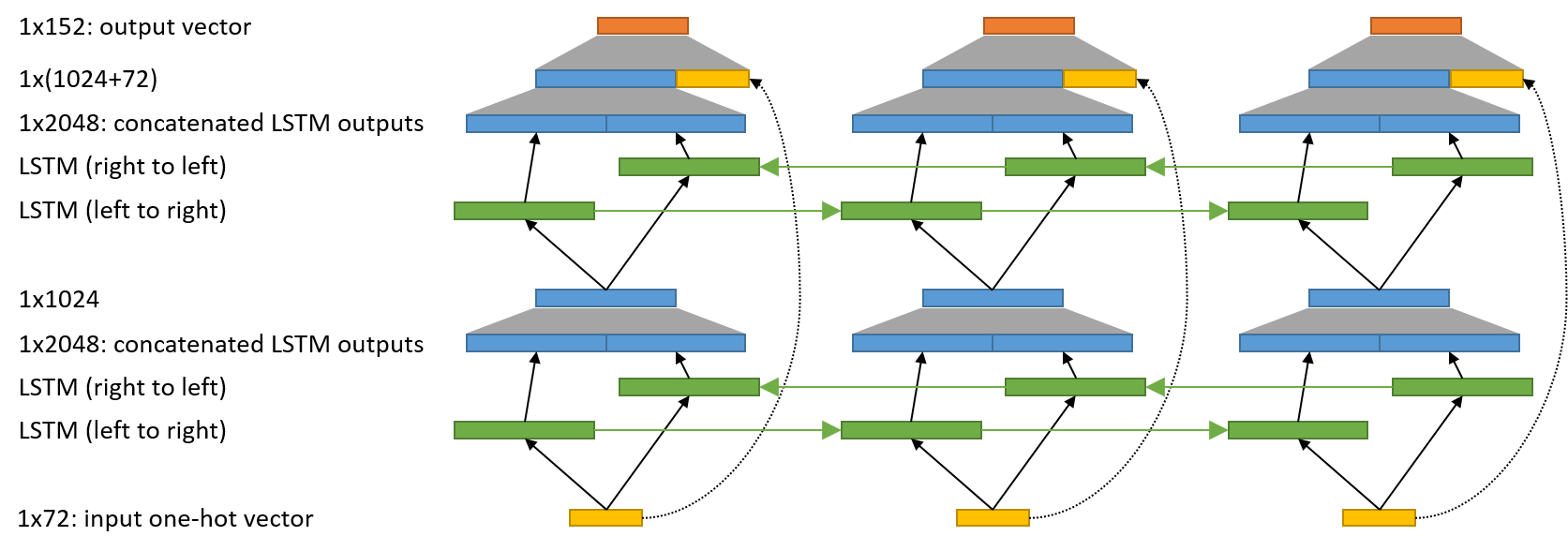 |
|---|
| Network architecture. Green boxes encapsulate all the magic inside LSTM. Grey trapezoids denote dense connections. Dotted line is an identity connection without trainable parameters. |
These 30 one-hot vectors are passed to the first layer of bidirectional LSTM. Basically it is a combination of two separate LSTMs, first one is passing over the sequence from left to right, and the other is passing from right to left. We use 1024 neurons in all LSTMs. Both LSTMs output some 1024-dimensional vectors at every position. These outputs are concatenated into a 2048 dimensional vector and are passed through another dense layer that outputs a 1024 dimensional vector. That’s what we call one layer of a bidirectional LSTM. The number of such layers is another hyperparameter (--depth). Our experiments showed that 2 layers learn better than 1 or 3 layers.
At every position the output of the last bidirectional LSTM is concatenated with the one-hot vector of the input forming a 1096 dimensional vector. Then it is densely connected to the final layer with 152 neurons on which softmax is applied. The total loss is the mean of the cross entropy losses of the current sequence.
The concatenation of the input vector to the output of the LSTM is similar to the residual connections introduced in deep residual networks. Some of the transliteration rules are very easy and deterministic, so they can be learned by a diagonal-like matrix between input and output vectors. For more complex rules the output of LSTMs will become important. One important difference from deep residual networks is that instead of adding the input vector to the output of LSTMs, we just concatenate them. Also, our residual connections do not help fighting the vanishing/exploding gradient problem, we have LSTM for that.
Results
We have trained this network using adagrad algorithm with gradient clipping (learning rate was set to 0.01 and was not modified). Training is not very stable and it’s very hard to wait until it overfits on our hardware (NVidia GTX 980). We use --batch_size 350 and it consumes more than 2GB of GPU memory.
python -u train.py --hdim 1024 --depth 2 --seq_len 30 --batch_size 350 &> log
The model we got for Armenian was trained for 42 hours. Here are the plots of training and validation sets:
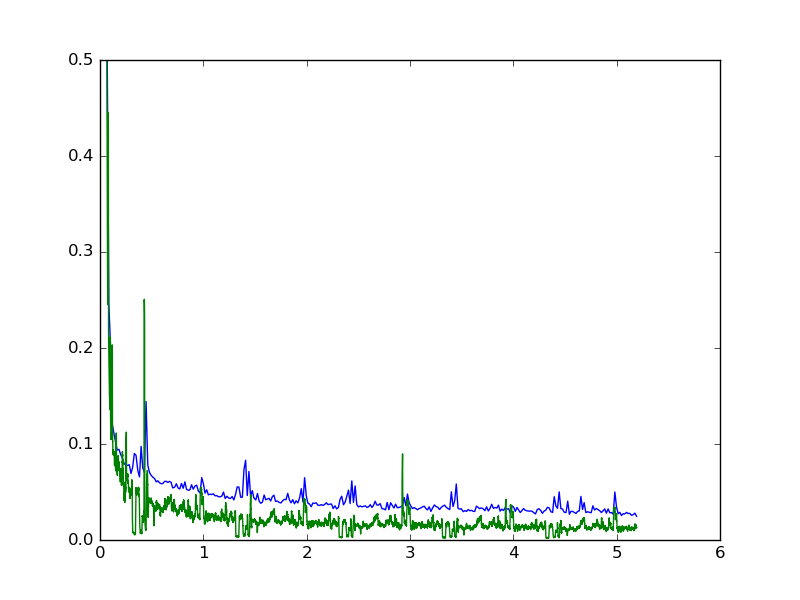 |
|---|
| Loss functions. Green is the validation loss, blue is the training loss. |
The loss quickly drops in the first quarter of the first epoch, then continues to slowly decrease. We stopped after 5.1 epochs. The Levenshtein distance between the original Armenian text and the output of the network on the validation test is 405 (the length is 36694). For example, hayeren.am’s converter output has more than 2500 edit distance.
Here are some results.
| Romanized snippet from Wikipedia (test set) | Transliteration by translit-rnn |
|---|---|
| Belgiayi gyuxatntesutyuny Belgiayi tntesutyan jyuxeric mekn e։ Gyuxatntesutyany bnorosh e bardzr intyensivutyune, sakayn myec che nra der@ erkri tntesutyan mej։ Byelgian manr ev mijin agrarayin tntesutyunneri erkir e։ Gyuxatntyesutyan mej ogtagortsvox hoghataracutyan mot kese patkanum e 5-ic 20 ha unecox fermernerin, voronq masnagitacats yen qaxaknerin mterqner matakararelu gorcum, talis en apranqayin artadranqi himnakan zangvatse։ | Բելգիայի գյուղատնտեսությունը Բելգիայի տնտեսության ճյուղերից մեկն է։ Գյուղատնտեսությանը բնորոշ է բարձր ինտենսիվությունը, սակայն մեծ չէ նրա դերը երկրի տնտեսության մեջ։ Բելգիան մանր և միջին ագրարային տնտեսությունների երկիր է։ Գյուղատնտեսության մեջ օգտագործվող հողատարածության մոտ կեսը պատկանում է 5-ից 20 հա ունեցող ֆերմերներին, որոնք մասնագիտացած են քաղաքներին մթերքներ մատակարարելու գործում, տալիս են ապրանքային արտադրանքի հիմնական զանգվածը։ |
Edit distance between this output and the original text is 0. Next we try some legal text in Armenian:
| Romanized snippet from Armenian constitution | Transliteration by translit-rnn |
|---|---|
| Zhoghovurdn ir ishkhanutyunn irakanatsnum e azat yntrutyunneri, hanraqveneri, inchpyes naev Sahmanadrutyamb naghatesvac petakan ev teghakan inqnakaravarman marminnyeri u pashtonatar anzanc midjocov: | հողովուրդն իր իշխանությունն իրականացնում է ազատ ընտրությունների, հանրաքվեների, ինչպես նաև Սահմանադրությամբ նախատեսված պետական և տեղական ինքնակառավարման մարմինների ու պաշտոնատար անձանց միջոցով: |
There is only one error here. The first word should start by Ժ and not հ. The possible reason for this is that the network doesn’t have a left-side context for that character.
An interesting feature of this system is that it also tries to learn when the Latin letters should not be converted to Armenian. Next example comes from a random Facebook group:
| Random post from a Facebook group | Transliteration by translit-rnn |
|---|---|
| aysor aravotyan jamy 10;40–11;00 ynkac hatvacum 47 hamari yertuxayini miji txa,vor qez pahecir txamardavari u vori hamar MERSI.,xndrum em ete kardas PM gri. p.s.anlurj, animast u antexi commentner chgreq,karevor e u lurj. | այսօր առավոտյան ժամը 10;40–11;00 ընկած հատվածում 47 համարի երթուղայինի միջի տղա,որ քեզ պահեցիր տղամարդավարի ու որի համար ՄԵՐSI.,խնդրում եմ եթե կարդաս ՊՄ գրի. p.s.անլուրջ, անիմաստ ու անտեղի ցոմմենտներ չգրեք,կարևոր է ու լուրջ. |
It is interesting that the sequence p.s. is not transliterated. Also it decided to leave half of the letters of MERSI in Latin which is probably because it’s written in all caps (Wikipedia doesn’t contain a lot of text in all caps, maybe except some abbreviations). Also, the word commentner is transliterated as ցոմմենտներ (instead of քոմենթներ), because it’s not really a romanized Armenian word, it just includes the English word comment (and it definitely doesn’t appear in Wiki).
Future work
First we plan to understand what the system actually learned by visualizing its behavior on different cases. It is interesting to see how the residual connection performed and also if the network managed to discover some rules known from Armenian orthography.
Next, we want to bring this tool to the web. We will have to make much smaller/faster model, translate it to Javascript, and probably wrap it in a Chrome extension.
Finally, we would like to see this tool applied to more languages. We have released all the code in the translit-rnn repository and prepared instructions on how to add a new language. Basically a large corpus and probabilistic romanization rules are required.
We would like to thank Adam Mathias Bittlingmayer for many valuable discussions.